Extreme Scale Unstructured Adaptive CFD: From Multiphase Flow to Aerodynamic Flow Control
Project Description
Tier 2 Code Development Project
Numerical Methods/Algorithms
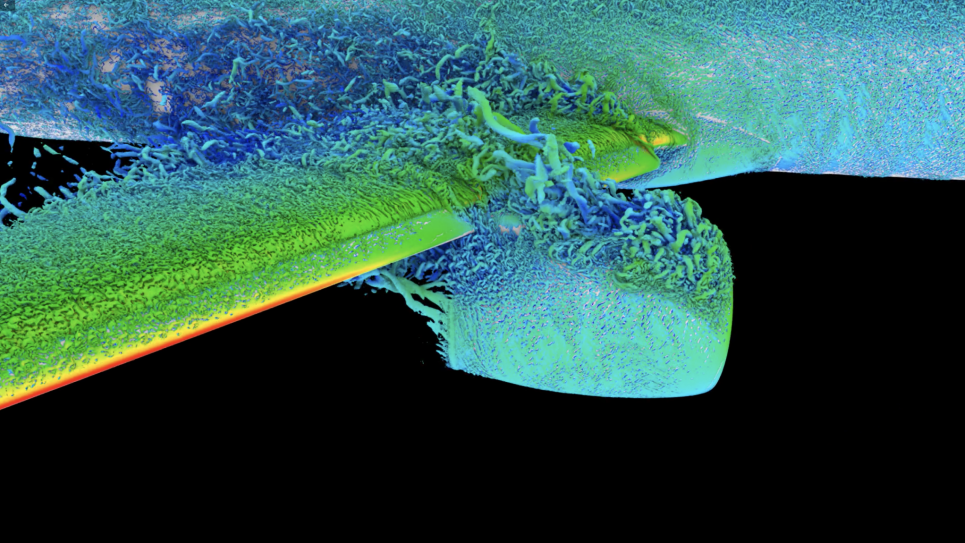
A mature finite-element flow solver (PHASTA) is paired with anisotropic adaptive meshing procedures. PHASTA is a parallel, hierarchic (2nd to 5th order accurate), adaptive, stabilized (finite-element) transient analysis solver for compressible or incompressible flows.
Parallelization
PHASTA has been coded for flat MPI and MPI+X where X is either part-based threads or more fine-grained task-based threads. While MPI+X has been shown to scale at better than 75% efficiency on a variety of architectures, on Mira, flat MPI has scaled at > 90% efficiency.
Application Development
- While the researchers have seen very good scaling of MPI only out to 60 ranks per node on KNC systems, they will study two other options
- MPI inter-node, with MPI endpoints within nodes
- Other lightweight/reduced thread-based on-node MPI variants (e.g., PCU or FineGrainMPI)
- Even more fine-grain thread parallelism already developed and demonstrated in PHASTA, and this will also be pursued
- Use DOE CODES developments to model dragonfly communication patterns, to predict how PHASTA’s communications will scale on Theta and Aurora
Portability
To maintain a truly portable option, and to provide another alternative fine-grained parallelism, the research team will also develop a parallel paradigm where the MPI process count is substantially smaller than the total number of computational cores (including GPU cores). Work for parts assigned to these processes is distributed to threads. CPU-GPU systems, where high-bandwidth memory per core is much smaller than on Theta, will require finer-grained parallelism (e.g., down to interior loops of the integral quadrature operations using OpenMP or similar).
Domains
Allocations