Tier 2 Code Development Project
Numerical Methods/Algorithms
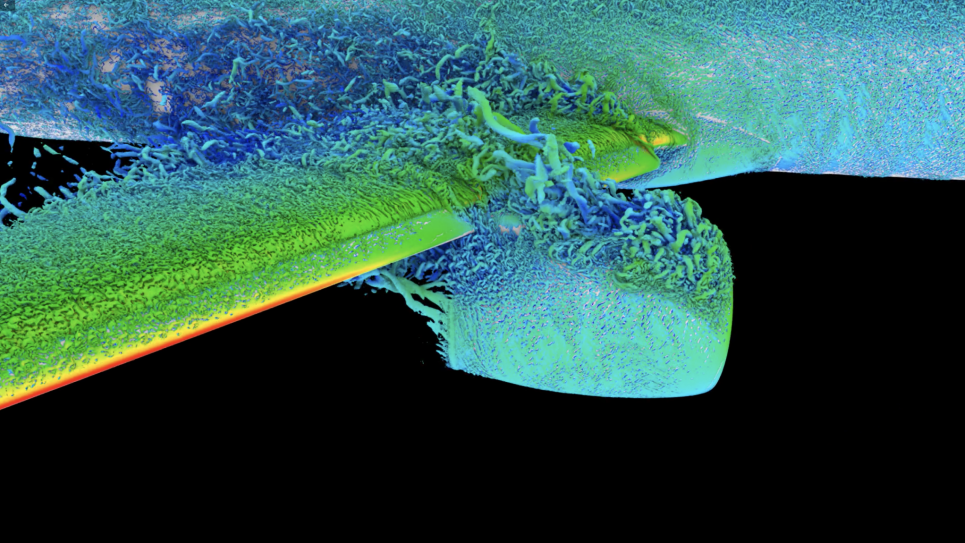
Direct numerical simulations for this project will be based on the open source spectral element solver Nek5000 developed at Argonne National Laboratory extended by the plugin for the simulation of low Mach number reactive flows developed at the Aerothermochemistry and Combustion Systems Laboratory of the Swiss Federal Institute of Technology Zurich (ETH).
Parallelization
Nek5000 uses MPI, and an OpenACC variant is under development. On Blue Gene/Q systems, Nek5000 has been scaled successfully to hundreds of thousands of cores. Current intranode-parallelism work with OpenACC will apply to OpenMP intranode parallelism on Theta.
Application Development
- From previous efforts on OpenACC, multithreading, and accelerators, the team has a deep understanding of the active memory traffic within a single rank. They expect to be able to directly exploit the KNL MCDRAM (e.g., through selective copying to properly declared temporaries).
- Strong scalability of Nek5000 allows it to run with very few points per rank, with a very small memory footprint. Because of this, the team’s fastest runs on Theta could fit entirely within the high-bandwidth on-package MCDRAM.
- Intranode performance on NxN operator matrices have been vectorized on CPU systems, but on GPUs, a different loop structure exposes parallelism across the spectral elements within an MPI rank. A recent OpenACC port of NekCEM (related code) sustained high GPU performance across Titan with this approach. If there is OpenACC support on Theta, this work will carry over directly; if only OpenMP is available, much of the effort will still be of value.
Portability
Nek5000 has been an early adapter on a diverse range of platforms from its inception. Over the past three decades, researchers have written specialized accelerator code, assembly code, and multithreaded variants for systems that have come and gone. Researchers recently completed a full port of NekCEM (which, as an explicit timestepper, is a bit simpler than Nek5000) to OpenACC and realized a 40:1 GPU:CPU performance gain on Titan with both the PGI and Cray compilers. As part of their OpenACC effort, the team has made the interface of their math libraries architecture transparent, just as they have done with MPI.