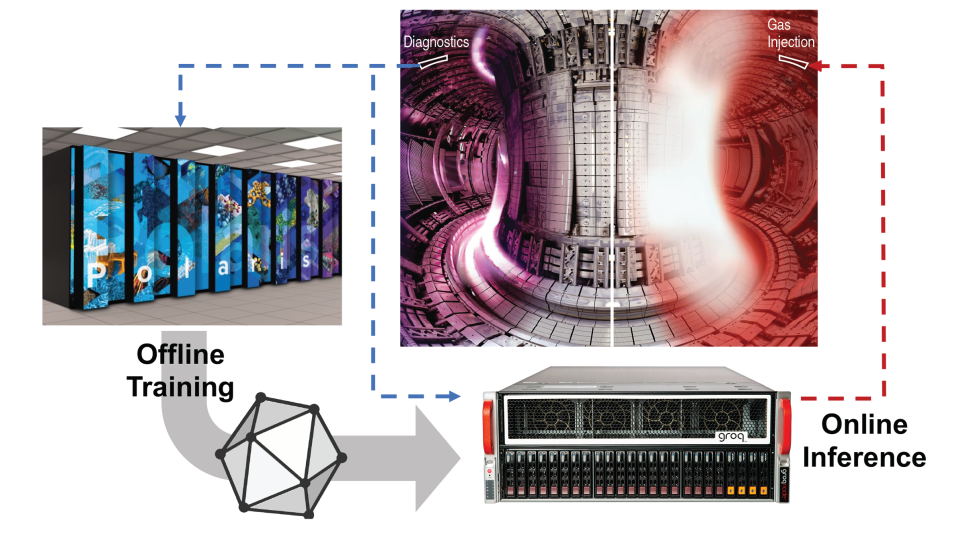
Researchers are leveraging the Groq AI platform at the Argonne Leadership Computing Facility’s (ALCF) AI Testbed to accelerate deep learning-guided investigations aimed at informing the operation of future fusion energy devices. The ALCF is a U.S. Department of Energy (DOE) Office of Science user facility at DOE’s Argonne National Laboratory.
Argonne computational scientist Kyle Felker oversees the deep learning fusion effort as a component of a larger project supported under the ALCF’s Aurora Early Science Program (ESP), which prepares applications for the lab’s forthcoming exascale supercomputer. Led by William Tang of DOE’s Princeton Plasma Physics Laboratory, the ESP project seeks to improve predictive capabilities and mitigate large-scale disruptions in burning plasmas in experimental tokamak systems such as ITER.
“A central problem with fusion has to do with control,” Felker explained. “The equations governing the behavior of a tokamak fusion reactor are extremely complex, and we have to figure out how to control the device such that instabilities don’t develop and prevent the fusion reaction from becoming self-sustaining. This is a massive engineering problem that requires a solution built on theory, simulation, machine learning, and human expertise.”
Real-time demands
Felker and colleagues turned to the ALCF AI Testbed to explore how novel AI accelerators could help advance their research. They found the Groq Tensor Streaming Processor (TSP) architecture enabled fixed, predictable compute times for a key phase of deep learning (inference) that would vary in duration if carried out on conventional high-performance computing resources powered by CPUs (central processing units) and GPUs (graphics processing units).
“We wanted to incorporate deep learning models in a real-time fashion,” Felker said. “To apply our trained models to try to obtain a prediction and then feed this prediction back to other fusion-reactor control systems, we have only a single millisecond.”
The research team’s tokamak application is unique among deep learning Aurora ESP projects for its real-time inference demands. The team intends to graduate use of the application to the prediction of instabilities in real-world plasma-discharge experiments being conducted as part of a path to viable fusion energy.
Argonne researchers envision the Groq platform in general as an edge computing device, operating in concert with other emerging AI hardware as well as GPU-accelerated machines. Ultimately, the finalized workflow for the fusion application is to be one that connects Aurora to an AI machine—Aurora for AI training, and the AI accelerator for inference.
Training versus inference
Different considerations inform the different phases of the deep learning process. While they are easy to conflate, training a model—in which a neural network learns how to meaningfully analyze datasets and use them to make predictions—is often performed in a distinct computational environment compared to the inference phase, when predictions are made with the trained model.
The team uses ALCF supercomputing resources to train models, and through the ESP allocation is preparing to leverage Aurora for massively parallel training.
“Deployment of the 2-exaflops Aurora system will enable training of models too large for existing computing systems,” Felker said.
Inference presents a problem for researchers. While training itself has no strict time limit (indeed, for the largest, most complex models, the process can take as long as several weeks), the time limit for inference is often highly constrained.
Consider the end goal of a smart fusion reactor.
“Even if you have a highly accurate trained model that can predict any possible plasma instability before it occurs, it is only useful if it can give reactor operators and automated response systems time to act. There cannot be any possibility that the AI machine will take a day or an hour or even a minute to generate a prediction,” Felker said.
Deterministic architecture
Given the significance of the inference problem, the team chose Groq as a platform on account of its TSP architecture. The TSP is designed to extend single-core performance across multiple chips, can perform inference tasks quickly, and is deterministic—it delivers consistent, predictable, and repeatable performance with zero overhead for context switching. As opposed to when carried out on a CPU- or GPU-based system, inference tasks will run on Groq for precisely the same amount of time in every instance.
“The lack of overhead you’d get with a GPU or CPU translates into a stronger guarantee that no jitter is introduced, whether that jitter delays performance by 50 microseconds or several milliseconds on account of some runtime stochasticity,” Felker explained.
The team envisions a smart fusion reactor backed by TSPs and GPUs where time-critical deep learning models run on the TSPs (e.g., when a disruption is imminent and unavoidable, and mitigating actions are required) and sophisticated reinforcement learning algorithms run on the GPUs (e.g., when researchers need to move the plasma to a more favorable state).
Tackling the fusion control problem with ONNX
Last year, Groq produced benchmarks for a limited number of cases. These results, as presented at last year’s AI Summit, suggested the TSP architecture might outperform GPUs when running the tokamak application.
The Groq Compiler has advanced considerably since then, enabling the use of a portable format called Open Neural Network Exchange (ONNX) for the team’s deep learning model.
ONNX is commonplace within the GPU- and CPU-based deep learning world as a mechanism for training a model on supercomputers and then saving it to disk in a portable, descriptive format that characterizes the architecture of neural network used for training while detailing the values of stored weights.
Afforded the ability to run ONNX files on the Groq TSP through the Groq Compiler, the team is now examining hundreds of different models to comprehensively investigate the fusion control problem. Given the rapid evolution of deep learning models, ONNX support is invaluable for facilitating rapid prototyping and deployment.
==========
The Argonne Leadership Computing Facility provides supercomputing capabilities to the scientific and engineering community to advance fundamental discovery and understanding in a broad range of disciplines. Supported by the U.S. Department of Energy’s (DOE’s) Office of Science, Advanced Scientific Computing Research (ASCR) program, the ALCF is one of two DOE Leadership Computing Facilities in the nation dedicated to open science.
Argonne National Laboratory seeks solutions to pressing national problems in science and technology. The nation's first national laboratory, Argonne conducts leading-edge basic and applied scientific research in virtually every scientific discipline. Argonne researchers work closely with researchers from hundreds of companies, universities, and federal, state and municipal agencies to help them solve their specific problems, advance America's scientific leadership and prepare the nation for a better future. With employees from more than 60 nations, Argonne is managed by UChicago Argonne, LLC for the U.S. Department of Energy's Office of Science.
The U.S. Department of Energy's Office of Science is the single largest supporter of basic research in the physical sciences in the United States and is working to address some of the most pressing challenges of our time. For more information, visit https://energy.gov/science