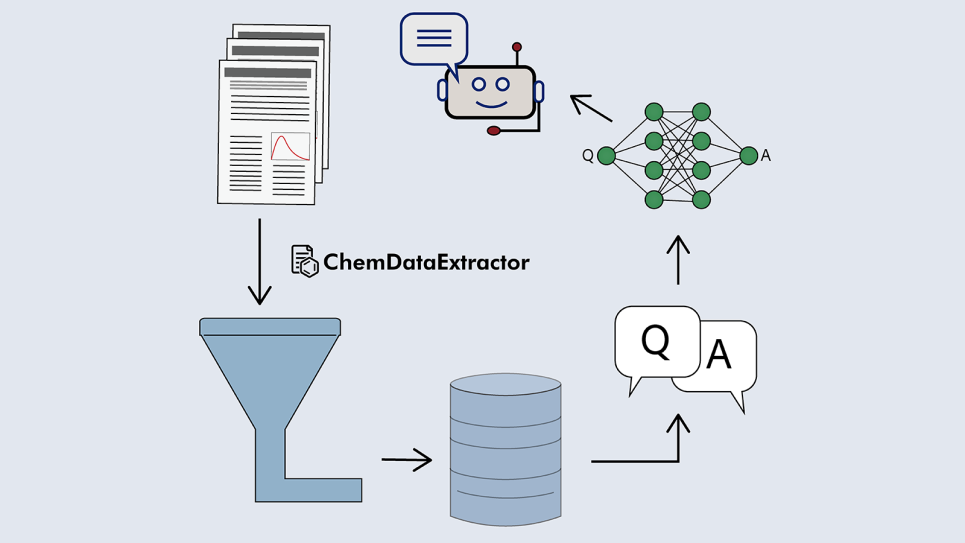
With support from supercomputers at the U.S. Department of Energy’s (DOE) Argonne National Laboratory, Jacqueline Cole and her team at the University of Cambridge are developing AI tools that automatically mine scientific journal articles to build structured materials databases. These datasets are then used to train specialized language models designed to streamline materials research.
“The aim is to have something like a digital assistant in your lab,” said Cole, who holds the Royal Academy of Engineering Research Professorship in Materials Physics at Cambridge, where she is Head of Molecular Engineering. “A tool that complements scientists by answering questions and offering feedback to help steer experiments and guide their research.”
Cole’s work at the Argonne Leadership Computing Facility (ALCF) began nearly a decade ago. In 2016, she was awarded one of the first projects under the ALCF Data Science Program, an initiative that broadened the facility’s support for workloads at the intersection of simulation, data science and machine learning. The now-retired program helped grow the community of researchers using ALCF resources for AI-driven science and expand staff expertise and capabilities to support this emerging area.
“Her team was among the first to use ALCF computing resources to combine machine learning with simulations and experimental results to advance data-driven materials research,” said Venkat Vishwanath, AI and machine learning team lead at the ALCF. “From developing the ChemDataExtractor text-mining tool to building automated databases from research papers, their work has opened new paths for accelerating materials design and discovery.”
In recognition of the team’s innovative work, Cole and collaborators recently won the Royal Society of Chemistry’s 2025 Materials Chemistry Horizon Prize for their paper “Design-to-Device Approach Affords Panchromatic Co-Sensitized Solar Cells.” Building on this research, Cole has continued to use ALCF supercomputers to develop AI tools aimed at speeding up the search for new materials used in energy applications, light-based technologies, and mechanical engineering.
Cole’s recent work has focused on developing smaller, faster, and more efficient AI models to support materials research, without the massive computing costs that are typically required to train large language models (LLMs) from scratch.
LLMs are AI models designed to process and generate human language. Building an LLM begins with pretraining it on a large dataset, such as a corpus of text, to help the model learn general language patterns. This process typically requires significant computing power. Once the model is trained, researchers then fine-tune it using smaller, more targeted datasets to ensure that it provides accurate and relevant answers.
To bypass the costly pretraining process, Cole and colleagues developed a method for generating a large, high-quality question-and-answer (Q&A) dataset from domain-specific materials data. Using new algorithms and their ChemDataExtractor tool, they converted a database of photovoltaic materials into hundreds of thousands of Q&A pairs. This process, known as knowledge distillation, captures detailed materials information in a form that off-the-shelf AI models can easily ingest.
“What’s important is that this approach shifts the knowledge burden off the language model itself,” Cole said. “Instead of relying on the model to ‘know’ everything, we give it direct access to curated, structured knowledge in the form of questions and answers. That means we can skip pretraining entirely and still achieve domain-specific utility.”
Cole’s team used the Q&A pairs to fine-tune smaller language models, which went on to match or outperform much larger models trained on general text, achieving up to 20% higher accuracy in domain-specific tasks. While their study focused on solar-cell materials, the approach could be applied broadly to other research areas.
Alongside this work, the team has pursued related studies to develop language models tailored to specific domains of materials science. In one paper, Cole’s team built a massive database of stress-strain properties for materials that are commonly used in mechanical engineering fields like aerospace and automotive. The researchers also developed MechBERT, a language model trained to answer questions about stress-strain properties, which outperforms standard tools in predicting material behavior under stress.
In another recent study, the team showed how to adapt language models for optoelectronics using 80% less computational power than traditional training methods without sacrificing performance.
Together, these efforts, along with the many studies Cole’s team has published over the past decade with ALCF support, illustrate how AI is transforming materials science research. With its recent focus on question-answering datasets, the team is making AI models more accessible to a broader community, paving the way for AI tools that can provide more precise and relevant support to experimentalists.
“Maybe a team is running an intense experiment at 3 a.m. at a light source facility and something unexpected happens,” Cole said. “They need a quick answer and don’t have time to sift through all the scientific literature. If they have a domain-specific language model trained on relevant materials, they can ask questions to help interpret the data, adjust their setup and keep the experiment on track.”
Ultimately, Cole believes this approach could help further democratize AI in materials science. “You don’t need to be a language model expert,” she said. “You can take an off-the-shelf language model and fine-tune it with just a few GPUs, or even your own personal computer, for your specific materials domain. It’s more of a plug-and-play approach that makes the process of using AI much more efficient.”
By doing the heavy lifting on ALCF’s powerful supercomputers, Cole’s team is advancing the development of more targeted and user-friendly AI tools that help materials scientists keep pace with the ever-growing amount of literature, design better experiments, and make discoveries more quickly.
The team’s work was supported by ALCF computing resources allocated through DOE’s ASCR Leadership Computing Challenge and the ALCF Director’s Discretionary program. The ALCF is a DOE Office of Science user facility.