Challenge
Large language models (LLMs) show promise for answering scientific questions, but training them from scratch on domain-specific data requires enormous computing resources. Even fine-tuning general-purpose models can be less effective if the training data lacks the precision needed for specialized scientific tasks. For many areas of materials science, there are also gaps in the availability of structured, machine-readable property data to enable such training.
Approach
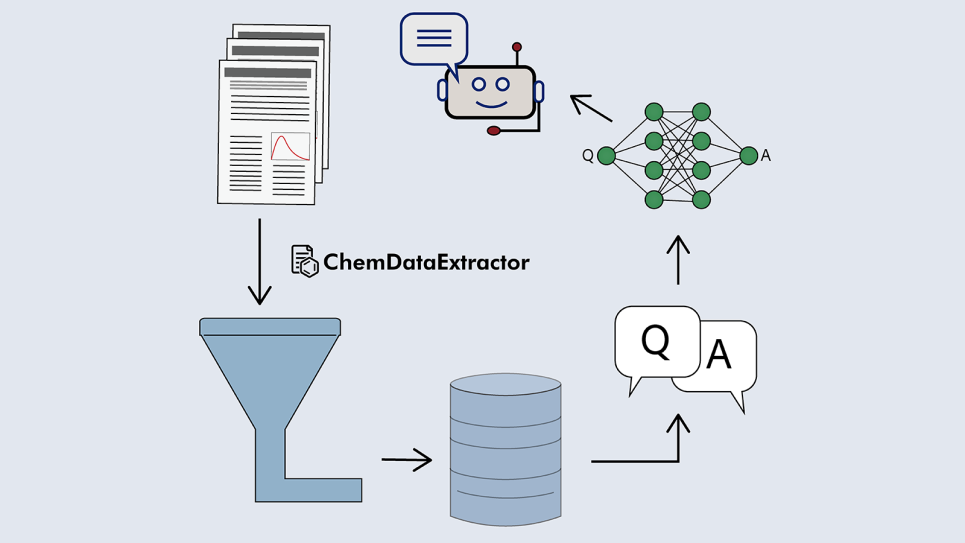
To overcome these barriers, researchers are leveraging ALCF resources to combine automated text mining with innovative AI training approaches. Using their ChemDataExtractor natural language processing toolkit, the team auto-generates high-quality datasets from scientific articles and builds structured materials databases, which are then fed into small, efficient language models, bypassing the need for costly pretraining of archetypical LLMs. ALCF supercomputers have been central to developing these workflows, enabling large-scale data extraction, algorithm development, and model training.
Results
In one study, the team transformed a photovoltaic materials database into hundreds of thousands of structured question-and-answer (QA) pairs, achieving up to 20% higher accuracy on solar cell–related tasks than models trained on general-purpose data. They applied the same strategy to other domains, including building a stress–strain property database with more than 720,000 records to train MechBERT, a model that outperforms standard tools in predicting material behavior under stress. Another project targeted optoelectronics, showing that domain-adaptive pretraining can be done with over 80% less computational cost than traditional methods while maintaining or improving accuracy. Most recently, the group generated nearly 100,000 QA pairs from a thermoelectric materials database, demonstrating that a small BERT model fine-tuned on this dataset, and further improved by mixing it with a general-purpose dataset, can outperform models trained on either source alone.
Impact
By turning unstructured literature into targeted, machine-readable knowledge, the team is making AI tools more accessible to the materials research community. Together, their efforts illustrate a scalable approach to building smaller, faster language models for specialized materials science domains and help scientists tailor models to their own areas, design better experiments, interpret results, and accelerate the path from discovery to application.
Publications
Kumar, P., S. Kabra, and J. M. Cole. “A Database of Stress-Strain Properties Auto-generated from the Scientific Literature using ChemDataExtractor,” Scientific Data (November 2024), Springer Nature.
https://doi.org/10.1038/s41597-024-03979-6
Kumar, P., S. Kabra, and J. M. Cole. “MechBERT: Language Models for Extracting Chemical and Property Relationships about Mechanical Stress and Strain,” Journal of Chemical Information and Modeling (January 2025), American Chemical Society.
https://doi.org/10.1021/acs.jcim.4c00857
Li, Z., and J. M. Cole. “Auto-generating Question-Answering Datasets with Domain-Specific Knowledge for Language Models in Scientific Tasks,” Digital Discovery (February 2025), Royal Society of Chemistry.
https://doi.org/10.1039/D4DD00307A
Sierepeklis, O., and J. M. Cole. “Autogenerating a Domain-Specific Question-Answering Data Set from a Thermoelectric Materials Database to Enable High-Performing BERT Models,” Journal of Chemical Information and Modeling (August 2025), American Chemical Society.
https://doi.org/10.1021/acs.jcim.5c00840