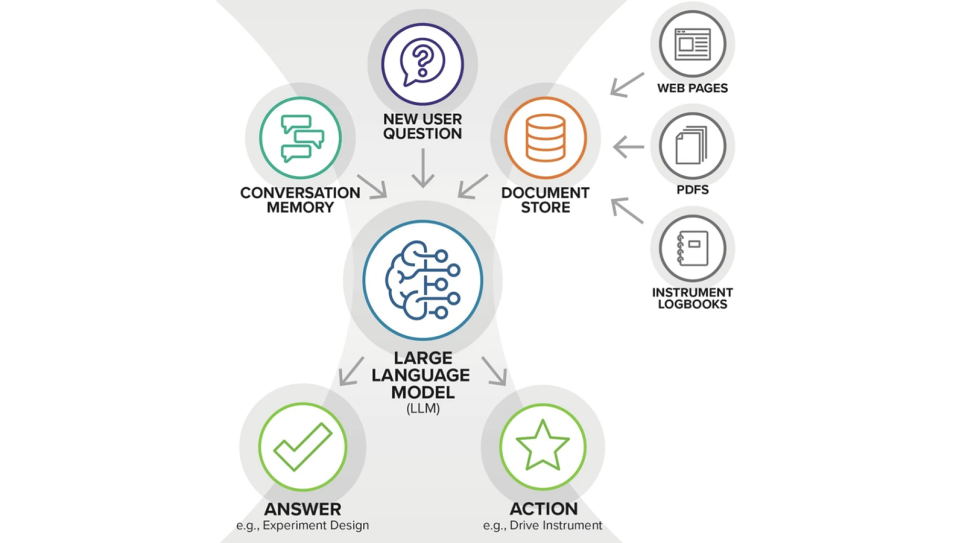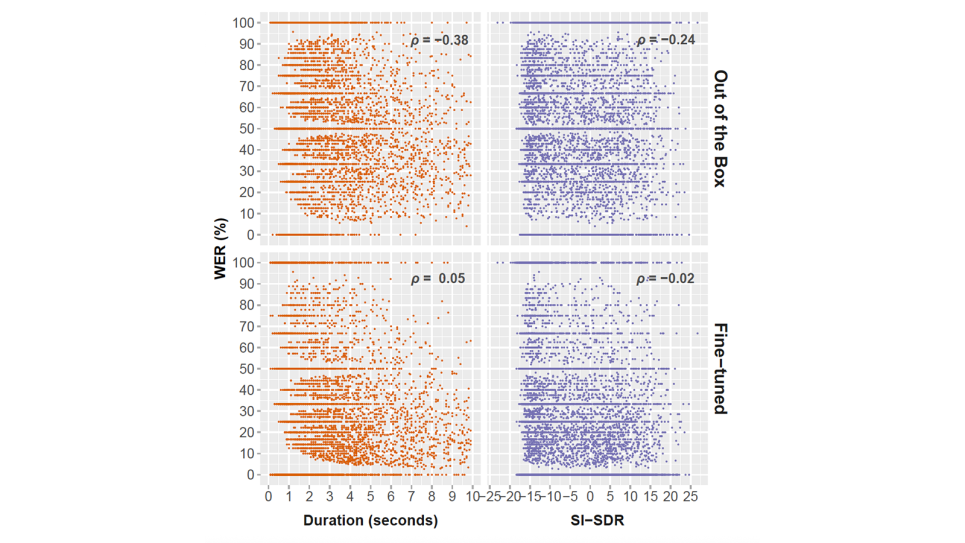
Word error rate (WER) vs. audio quality (SI-SDR) and utterance duration for NeMo FastConformer CTC (616M) on the dev set. (Image: Christopher Graziul, University of Chicago)
Word error rate (WER) vs. audio quality (SI-SDR) and utterance duration for NeMo FastConformer CTC (616M) on the dev set. (Image: Christopher Graziul, University of Chicago)
Word error rate (WER) vs. audio quality (SI-SDR) and utterance duration for NeMo FastConformer CTC (616M) on the dev set. (Image: Christopher Graziul, University of Chicago)
Police radio communications are a unique source of information about everyday police activity and emergency response, offering valuable insights for research into law enforcement operations and public safety. However, these audio streams are often noisy and difficult to transcribe accurately, especially at scale. A team of researchers is using ALCF computing resources to evaluate and improve automatic speech recognition (ASR) systems for police radio, enabling more effective analysis of this valuable data source.
Broadcast police communication (BPC) audio is challenging for ASR systems due to multiple factors, including narrow-band audio channels, a multitude of speakers, background noise, and specialized vocabulary. Publicly available ASR systems, which are often trained on clean audio, struggle with high word error rates in this domain. Creating accurate transcripts is essential for downstream tasks such as event detection, call classification, and trend analysis, but retraining ASR models for BPC data requires substantial computational power and domain-specific expertise.
The team assembled a new corpus of roughly 62,000 manually transcribed police radio transmissions (about 46 hours of audio) from the Chicago Police Department to benchmark model performance. Using ALCF computing resources, they evaluated state-of-the-art ASR systems, including Whisper Large (v3), and customized ESPNet models with domain-specific token vocabularies and language models. Their work involved using multiple audio feature extractors, including log Mel-filterbank features, HuBERT Large, WavLM Large, and a feature fusion model, and conducting large-scale fine-tuning on the ALCF’s Polaris supercomputer. In addition, the team performed detailed error analyses to identify recurring transcription failures and guide future improvements.
Baseline evaluations showed that off-the-shelf ASR models performed poorly on BPC audio, with high rates of substitution, deletion, and insertion errors. Fine-tuned models trained on Polaris achieved substantial accuracy gains over their baseline counterparts. The researchers also quantified inter-annotator agreement to better understand the inherent ambiguity in transcribing BPC, helping to set realistic performance expectations for ASR systems. Their work establishes new benchmarks for ASR performance in police radio transcription and provides a framework for systematically improving accuracy in this domain.
By advancing speech recognition for noisy, domain-specific audio like police radio communications, this work supports the development of tools for analyzing public safety and emergency response data. The team made its large corpus of police radio transmissions, along with the associated data annotation pipeline, available to the research community to enable further study on the large-scale transcription and analysis of police communications.
Srivastava, T., J.-C. Chou, P. Shroff, K. Livescu, and C. Graziul. “Speech Recognition for Analysis of Police Radio Communication,” 2024 IEEE Spoken Language Technology Workshop (December 2024), IEEE.
https://doi.org/10.1109/SLT61566.2024.10832157